General overview¶
As discussed in the previous chapter, one of the suggestions made at the Sixth edition of the IPC was to set up three different components for organizing an IPC: a SVN repository, a wiki site and the computer facilities that actually run all the experiments.
The following sections discuss all these parts separately and how they have been used in the Seventh International Planning Competition. At least, the first section (SVN repository) is important for organizers of other Competitions as well as for people administering the IPC software in a closed environment. Users of the IPC software can safely skip all these sections and go directly to IPCData. The last section is devoted to this documentation.
Warning
The software of the Seventh International Planning Competition and all its documentation shown here are licensed under the GNU General Public License version 3. For more information refer to the GNU GENERAL PUBLIC LICENSE. For further enquiries regarding other distribution licenses directly contact the author: Carlos Linares Lopez, carlos.linares@uc3m.es.
Warning
A word of warning for readers of this manual. While all the features described herein refer to the latest version of the software distributed through the official svn server, some might be available only from a particular version. Therefore, if some are not apparently available in your installation invoke your script with the directive --version to make sure that it matches the minimum requirements specified in this manual and consider updating if that is not the case.
SVN repository¶
This section justifies the suitability of using SVN repositories and then provides details about the arrangement of contents in the two repositories available after the Seventh International Planning Competition.
Advantages of using SVN repositories¶
The idea of using a SVN repository allows:
Everyone to download and use the same data
This means that, at least, planners and domains shall be stored at the SVN repository so that everyone can download them.
Besides, storing the scripts used for running experiments and reporting results would be highly desirable as well since this would allow everyone to use the same framework for making experiments.
Provides a single point that can be copied across different computers.
This means that the organizers of a particular IPC can easily make backup copies while everyone is welcome to make copies of the repository to their own computers for making her own experiments in a private environment prior to new publications or the development of new planners for the incoming IPCs.
A SVN repository with the results of all the experiments guarantees the repetibility of the same experiments and provides means for making cross validations
While providing logs of the executions is highly desirable for showing the competitors/researchers that apparently nothing went wrong, allowing everyone to have a look at the particular results enables various techniques for cross validating the results produced at the International Planning Competition or the experiments conducted at the lab.
The contents and arrangement of data in both repositories is discussed in the next subsection. Throughout all this documentation, the tracks and subtracks are abbreviated as follows:
Acronym legend seq sequential track tempo temporal track sat satisficing subtrack mco satisficing multi-core opt optimal subtrack
so that, for example, seq-opt stands for the sequential satisficing track and tempo-sat stands for the temporal satisficing track.
Contents of the data repository¶
The data repository contains both the planners that took part in the Seventh International Planning Competition, all the domains that were chosen to evaluate them and summaries of all the results gathered so far. Domains, planners and results are organized in the following tracks-subtracks: sequential satisficing (seq-sat), sequential optimal (seq-opt), sequential satisficing multi-core (seq-mco) and temporal satisficing (tempo-sat). Finally, the data repository also contains the scripts used at the IPC 2011 and the latest version of this documentation.
A copy of the repository used at the Seventh International Planning Competition is available at:
svn://svn@pleiades.plg.inf.uc3m.es/ipc2011/data
The current size of this repository is almost 1 Gb. Therefore, make sure to allocate space (and time) enough to check-out though it is not necessary at all to retrieve all the domains and planners to make experiments. This section discusses below the organization of planners, domains and scripts. For an introduction to the summaries of the results see Inspecting data. A detailed copy of all the results can be accessed through a different svn repository, see Contents of the results repository.
The data repository is organized as follows. First, planners are arranged according to the following schema:
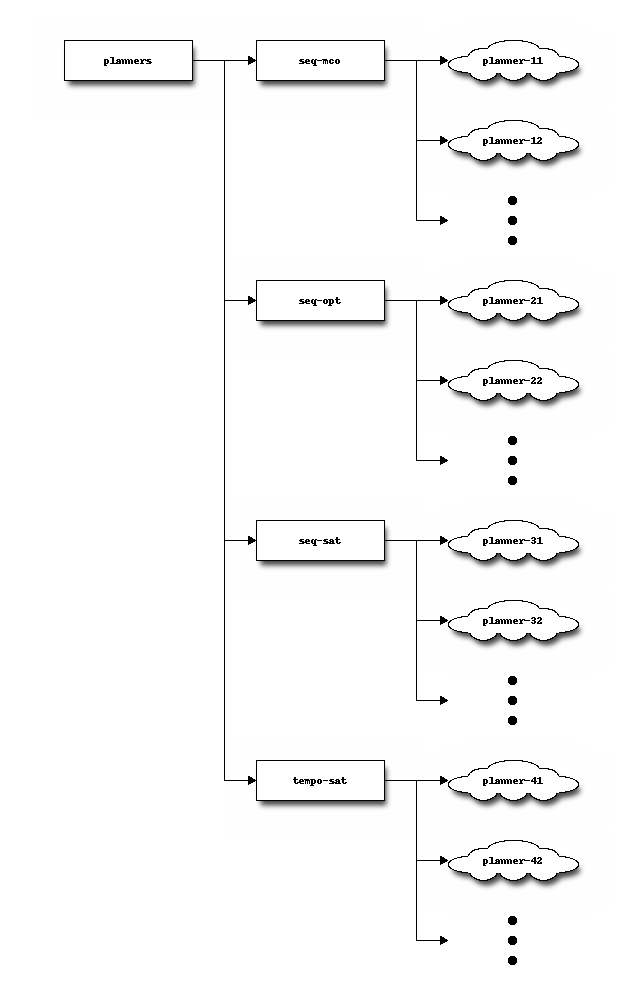
where planner-ij stands for a particular planner preceded by the track-subtrack. For example, the optimal planner forkinit is located at planners/seq-opt/seq-opt-forkinit/. The clouds shown in the figure above indicate that their content depend on the particular arrangement of every planner. However, the software of the Seventh International Planning Competition requires two particular scripts to be located at the root of these directories: build and plan —see check.py.
Next, domains are stored as follows:
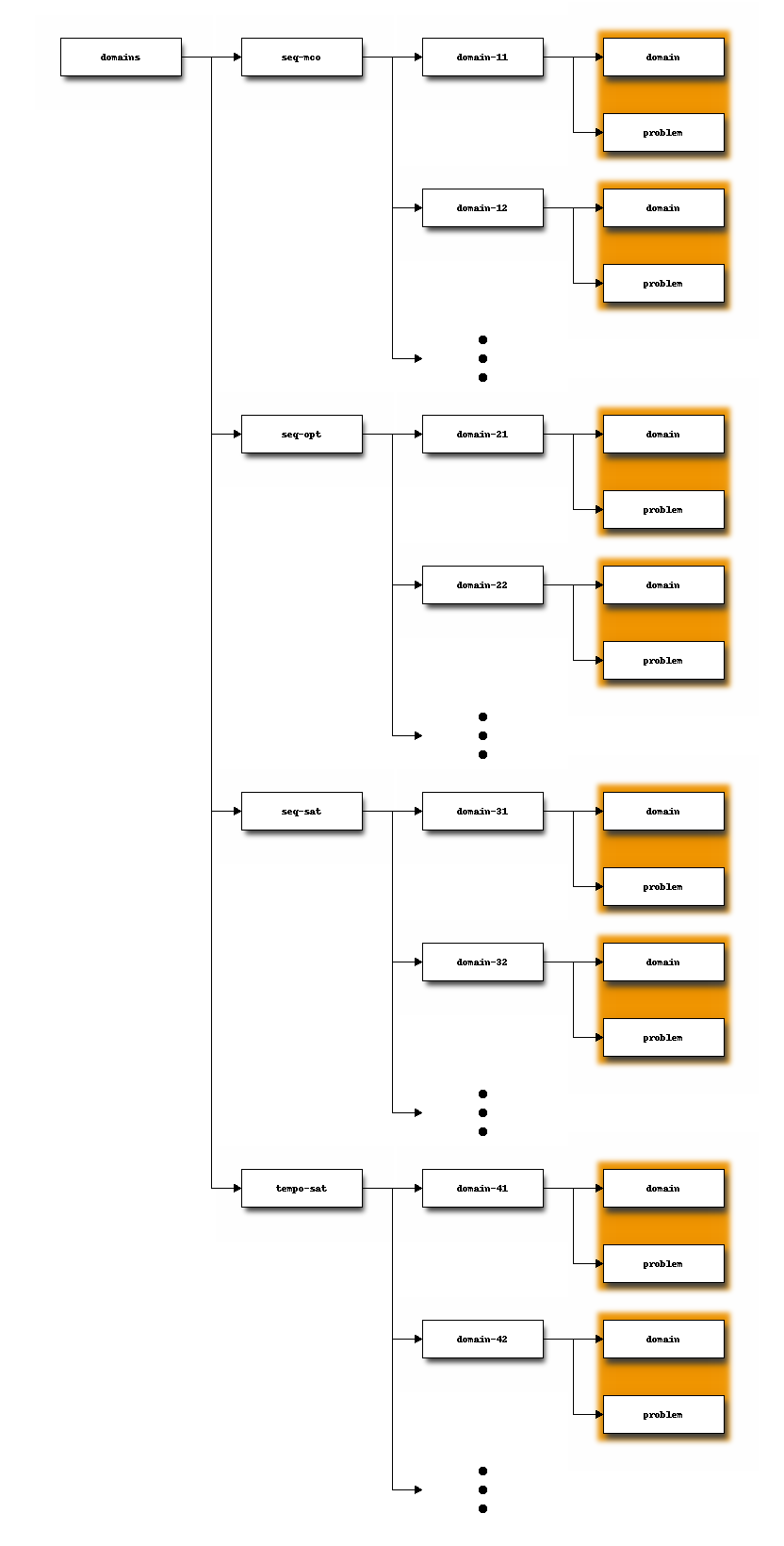
where domain-ij shall be substituted by the name of particular domain. For example, the domain floortile used in the sequential optimization track is located at domains/seq-opt/floortile/. The directories domain and problems are grouped to indicate that they define together a particular planning task.
Both, the names of planners and domains shall meet the following requirements:
planners: They can consist of any combinations of the alphabetic characters a-z either in lowercase or uppercase. Besides, the name also admits any digits and the special characters _ and -. Alternatively, a single dot . can be used followed by either an alphabetic character (either in lowercase or uppercase) or a digit.
For example, lama-2011, dae_yahsp and Multiplan.s are legal, whereas planner#1 or my.planner are not allowed. Besides, the blank space is strictly forbbiden.
On the other hand, as a convention (i.e., they are not affected in any way by any script), tracks-subtracks starting with the letter x are considered to be extra planners, i.e., running in the competition in non-competitive mode. This is the case, for example, of a second version of the planner ArvandHerd that was not accepted to take part competitively in the seq-mco competition. However, the experiments were run much the same and data with its results were disseminated in the same fashion. They can be found at planners/xseq-mco/xseq-mco-arvandherd/
domains: They can be made up only of a combination of alphabetic characters (either in lower or uppercase) and digits.
For example, nomystery or barman are legal names whereas visit-all would cause an error in some scripts.
Besides, a track-subtrack (i.e., directories immediately beneath domains) that starts with a t are considered test domains and they are treated as such by the script invokeplanner.py —see invokeplanner.py. For example, the directory domains/ttempo-sat/matchcellar/ contains the problems used for running preliminary tests.
This does not mean, however, that the tree structure presented above is rigid. Other directories can be included at any location. In this case, it is very important to make the following observations:
1. Directory names starting with any of the special characters _ or . (as in the case of the .svn directories) are always skipped at any level.
2. In the particular case of the domains structure, the arrangement discussed above is considered only when looking for particular domain.pddl and problem.pddl files. In the process, any other directories than those shown above are just ignored.
It is worth noting that tracks and subtracks can be given any name. This serves to differentiate different groups since the IPC scripts apply only to a particular combination of track-subtrack. This is, no cross-reference is done between different tracks-subtracks. However, there are two names for subtracks with a distinguished meaning:
mco: By default, the time bound given to invokeplanner.py is used to set a limit on the available time for all threads and/or processes started by a planner. For example, if the time limit is 30 minutes (1800 seconds) and a planner launches three threads, the sum of all the running times is checked and the planner is killed when this sum is equal or larger than 1800 seconds. However, when specifying the subtrack mco, the planner is given the specified time in spite of the number of processes and threads it launches. dck: This term stands for Domain Control Knowledge and it is one of the subtracks used at the Learning Competition of the Seventh International Planning Competition. In this particular case, planners shall be given a fourth parameter which specifies the location of the domain control knowledge, in contraposition to the typical case where only three parameters have to be specified (for more details see check.py).
Regarding the scripts, they are all located beneath scripts/. One tiny script was developed in awk for processing the results of the Sixth International Planning Competition for choosing problems for the IPC 2011 when reusing domains but has no other applicability and therefore its discussion is skipped here. However, the scripts beneath scripts/pycentral are of capital importance and it is expected that they will be also useful for the organizers of other Competitions as well as for researchers at their home labs. For a thorough discussion of the package IPCData see IPCData; the package IPCReport is discussed in IPCReport; finally, the package IPCPrivate is introduced in IPCPrivate.
Contents of the results repository¶
All the results generated during the IPC 2011 are available at:
svn://svn@pleiades.plg.inf.uc3m.es/ipc2011/results
Keep in mind that this repository is huge and contains 35+ Gb of data. Therefore, it is not recommend to check out its contents. Instead, it is better suited just to browse its contents for looking for particular results —to this end, there are various free software packages that make this task very easy such as eSVN for Linux and svnX for Mac OS. The organization of the results repository is much the same than any results directory. For a thorough discussion of its contents see The results directory.
To access the results in a manageable size, a number of snapshots have been generated and are accessible through the first repository either: just to inspect data (see section Inspecting data); to compute the score of a set of planners (see sections score.py and tscore.py) and even to perform statistical tests —see test.py.
Wiki site¶
Wikis provide effective means for sharing data rapidly in various formats at different levels. Besides, they do provide a friendly environment so that they have been used for formally presenting the contents and progress of the Seventh International Planning Competition.
The wiki for the IPC 2011 can be found at http://www.plg.inf.uc3m.es/ipc2011-deterministic
Any wiki engine would make the service. In particular, at the Sixth edition, the MoinMoin Wiki engine was selected and it was used again at the Seventh International Planning Competition.
One of the main advantages of using a Wiki is that they allow a number of private pages to be written for sharing data among organizers thanks to the so-called acl (access control lists) that allows different people to share data among them without ever letting others notice. Examples are: todo pages, domain candidates, partial results, etc.
Computer facilities¶
In the very end, an arbitrary number of planners shall be run on a particular selection of domains and problems on a computer. While most practitioners might found it useful to run their own experiments in their own personal computers (e.g., overnight) they are more likely to use other more capable facilities when running large experiments. Consider for example the case of making large experiments for tuning port-folios or, of course, the case of running either one particular International Planning Competition or to arrange a new one.
A cluster with eleven computers (one front-end and ten back-end nodes) was set up for the Seventh International Planning Competition. The front end is named pleiades, while the back-end nodes are: alcyone, atlas, electra, maia, merope, taygeta, pleione, celaeno, tau and asteropeI. Each node is an Intel Xeon 2.93 Ghz Quad Core processor (64 bits) using Linux. Up to 6 GB of RAM memory and 750 GB of hard disk were available for each planner. Each planner was run in a single node and no planner was allowed to run in more than one simultaneously —although in the multicore track it was allowed to use all the 4 cores of a node. No GPU processing was available.
Nevertheless, no assumptions are made about the underlying hardware running the experiments. However, they are expected to be GNU/Linux-based computers, the reason being that the script invokeplanner.py uses the /proc filesystem to retrieve various sets of system information —see invokeplanner.py
Documentation¶
This documentation is distributed both as a pdf file and html pages. Both formats are automatically generated with Sphinx.
This documentation is distributed under the terms of the GNU General Public License 3.0 (see GNU GENERAL PUBLIC LICENSE) and therefore you are very welcome to modify it, copy it and/or redistribute it. If you want to do so:
- The source files of this documentation can be retrieved with svn co svn://svn@pleiades.plg.inf.uc3m.es/ipc2011/data/doc
- If you plan to modify and recompile the source files *.rst, then:
2.a. Make sure to install Sphinx
2.b. This documentation uses a wonderful contribution named blockdiag. After installing it, make sure also to make it available to Sphinx by installing and configuring sphinxcontrib-blockdiag
Now, from the root directory of your documentation type:
make html
to obtain a new version of the html pages, or:
make latex
to obtain LaTeX source files which can then be processed to obtain the final pdf. More formats are available as shown by the following command:
make help